Threat Modeling: Citizens Versus Systems
[no description provided]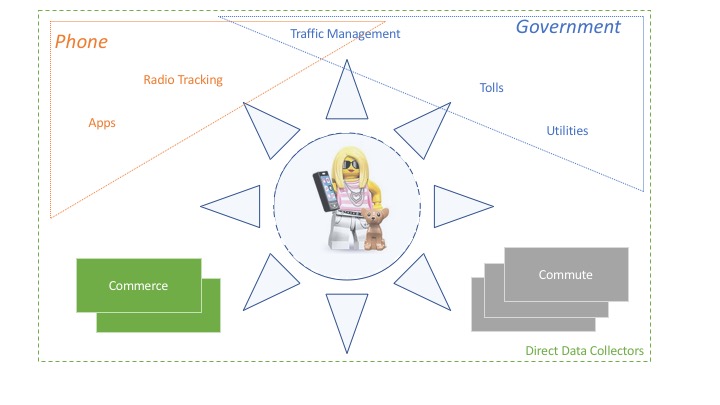
Recently, we shared [link to https://seattleprivacy.org/threat-modeling-the-privacy-of-seattle-residents/ no longer works] a privacy threat model which was centered on the people of Seattle, rather than on the technologies they use.
Because of that, we had different scoping decisions than I've made previously. I'm working through what those scoping decisions mean.
First, we cataloged how data is being gathered. We didn't get to "what can go wrong?" We didn't ask about secondary uses or transfers — yet. I think that was a right call for the first project, because the secondary data flows are a can of worms, and drawing them would, frankly, look like a can of worms. We know that most of the data gathered by most of these systems is weakly protected from government agencies. Understanding what secondary data flows can happen will be quite challenging. Many organizations don't disclose them beyond saying "we share your data to deliver and improve the service," those that do go farther disclose little about the specifics of what data is transferred to who. So I'd like advice: how would you tackle secondary data flows?
Second, we didn't systematically look at the question of what could go wrong. Each of those examinations could be roughly the size and effort of a product threat model. Each requires an understanding of a person's risk profile: victims of intimate partner violence are at risk differently than immigrants. We suspect there's models there, and working on them is a collaborative task. I'd like advice here. Are there good models of different groups and their concerns on which we could draw?