Threat Model Thursday: BIML Machine Learning Risk Framework
Risk Framework and Machine Learning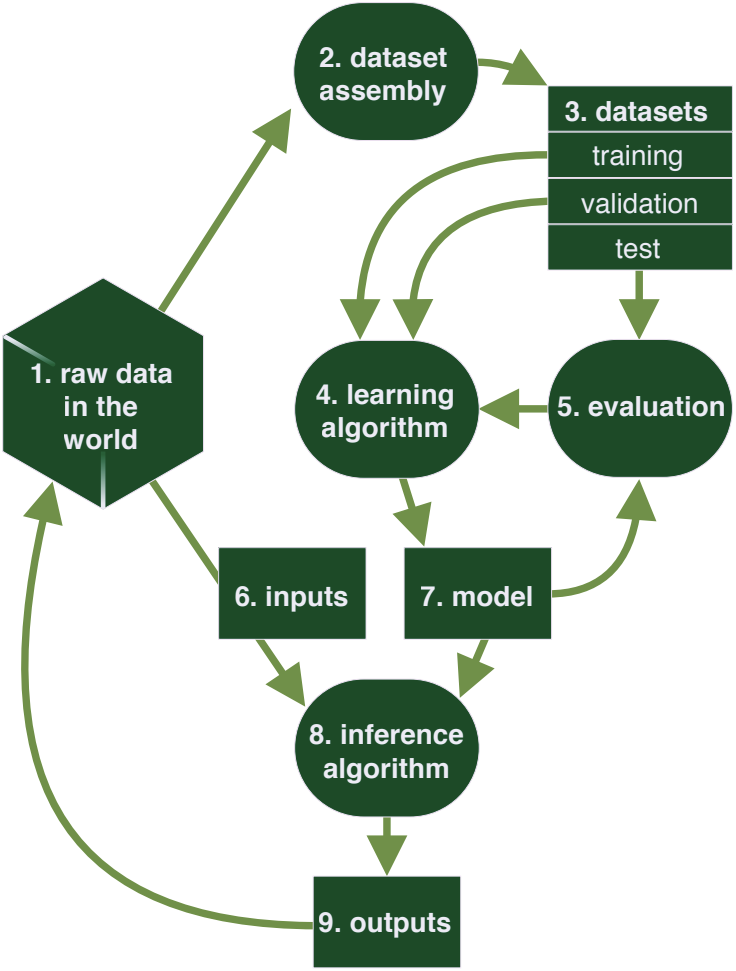
The Berryville Institute of Machine Learning (BIML) has released "An Architectural Risk Analysis of Machine Learning Systems." This is an important step in the journey to systematic, structured, and comprehensive security analysis of machine learning systems, and we can contrast it with the work at Microsoft I blogged about last month. As always, my goal is to look at published threat models to see what we can learn. Also, I'm following the authors' language here - Dr. McGraw and I have had discussions about the relationship between terms, and I don't think that there's much value in a fight over ARA vs TM, attack surface vs trust boundary, or threat vs risk.
BIML has released the work in two ways, an interactive risk framework contains a subset of the information in the PDF version. I'll focus on the PDF version (Version 1.0 (1.13.20)), which is formally divided into two parts. Part One is titled ML Security Risks, and Part Two is a set of principles. The authors communicate a nuanced understanding of those principles where they say "Some caveats are in order. No list of principles like the one presented here is ever perfect..." I have little to add except I would like a guarantee that if I follow their principles, my system will be secure (😀). And so I'll focus on Part One, which we can usefully divide into sections.
The first section of Part One is a threat analysis which follows the four question framework. They have a model of ML systems (reproduced at the top of this post). They address what can go wrong in a list of 78 specific risks, organized into both a top ten list and risks to each of the 9 components of their system. The by-component analysis also has sets of "associated controls", some of which tie to specific risks, others to specific components. This section doesn't contain controls for the system as a whole.
The specific risks are challenging in several ways. The first challenge is specificity. For example, risks to the raw data in the world include "raw:1:data confidentiality," and "raw:3:storage." I would think that risks to data confidentiality include those to storage, but a substantial part of what's covered in the former seems to be about how the data flows through and can be extracted from the outputs. I'm specifically not commenting that the risk applies in more than one place - rather I am puzzled at which issues I should be looking at in data confidentiality vs data storage. I would think that raw:3:storage would incorporate both confidentiality and integrity. The generality means that many of the risks (such as an attacker tampering with your inputs) recur, and that makes the list feel redundant and perhaps challenging to use. This also illustrates a tradeoff: had the authors applied their analysis to data flows, as well as processes and external entities, then my concern about overlap would be smaller, while my concern about redundancy would be larger.
There's also a challenge that the risks are quite dis-similar. Some of these seem like things attackers could do (text encoding), others like things which could go wrong (storage), others more the effects of things going wrong (legal). There are also some oddly named risks: tampering with input data is labeled 'trustworthiness'. Encoding integrity seems to relate to data selection. Encoding integrity relates closely (in my mind) to sensor risks. There are similar questions we can ask of the other parts of the system.
However, these are challenges, not fatal flaws. They can also be seen as usability challenges, the sort of thing which can be tested and measured, because we can see how well the document works for the intended audiences of ML practitioners and engineers, security practitioners, and ML security people. (I suspect it will work better for group 3, and again, that's a testable hypothesis.)
Section B is a map of attacks. (They say "You can think of a specific attack as a coordinated exploit of a set of risks that results in system compromise. For the most part we will ignore attacks on ML infrastructure or attacks that specifically circumvent ML-based defense." I think they are here using 'system compromise' in the sense of 'mission compromise,' rather than 'popping a shell.'
Section C is a very brief attack surface estimation. (Probably appropriately brief.)
Section D is a set of ten "system wide risks and broad concerns." I think of this as a second threat analysis, looking at risks that are, well, system-wide, rather than component-specific. It is a good complement to section A, and in the title and orientations of the risks are much more self-similar than in section A.
All of that said, let's step back and take a look at what's here. There are three lists of risks:
- A Top Ten (extracted from the 78)
- 78 specific risks, which I'm going to dub the BIML-78
- 10 System-wide risks
It would be helpful if the authors would explicitly tie the 78 to one or the other or both lists of ten, and to apply the Spinal Tap treatment to one or the other, and make it go to 11, to mitigate risks of confusion. There's an implication of only including the BIML-78 in the interactive page, and I am unsure why that means. Also, the lists need names. (See promoting threat modeling work, bullet 2.)
Obviously, this set is different thing than STRIDE. Both help us answer the question of 'what can go wrong?' so in that frame, they're similar. But the BIML-78 (v1) seems more like a library than a mnemonic, checklist or prompt. (Somewhat entertainingly, there are 78 threat cards in an Elevation of Privilege deck - there's obviously a need for a card deck!)
It is interesting that the threats are tied to elements of the system design - that's a somewhat unusual property, and one that we'll also see in next week's TM Thursday post.
It would also be helpful to hear when and how each list (especially the long one) is intended to be used. The analysis seems like a longer, more elaborate project than a session using STRIDE to analyze a system. Is the plan a set of meetings in which senior engineers discuss the threats?
In summary, I think that this is more usefully viewed as an analysis, rather than an analytic tool, and that its core could be built into an analytic tool.
Update: The top ten are explicitly pulled from the BIML-78, and tagged as such in the text. My apologies.