Threat Model Thursday: Google on Kubernetes
[no description provided]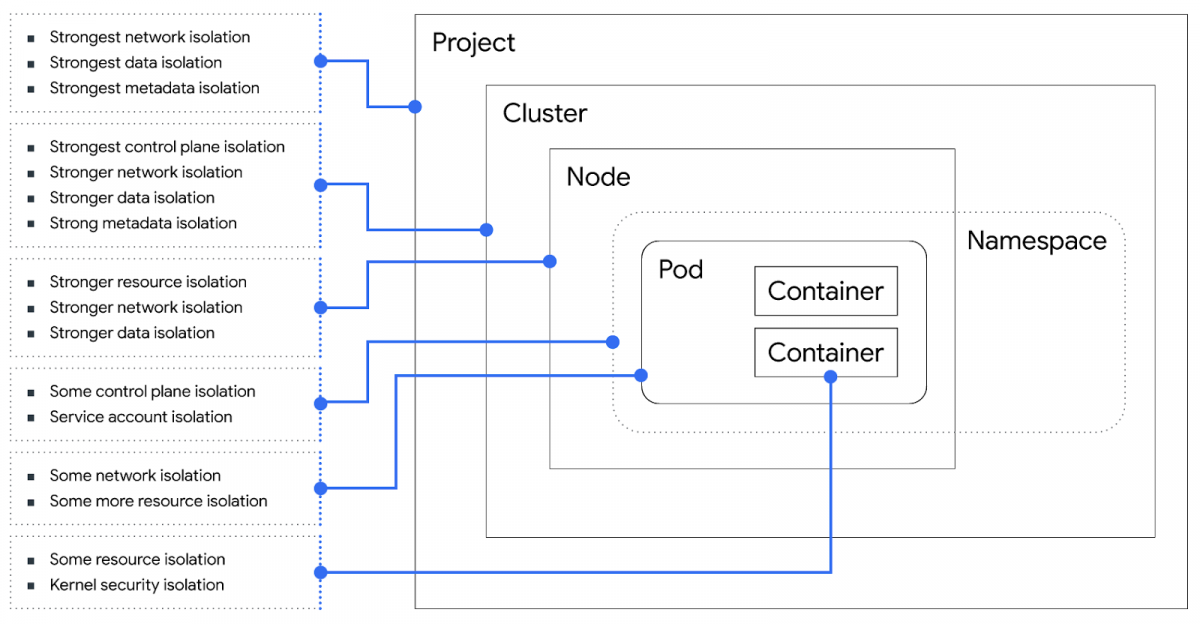
There's a recent post on the Google Cloud Platform Blog, "Exploring container security: Isolation at different layers of the Kubernetes stack" that's the subject of our next Threat Modeling Thursday post. As always, our goal is to look and see what we can learn, not to say 'this is bad.' There's more than one way to do it. Also, last time, I did a who/what/why/how analysis, which turned out to be pretty time consuming, and so I'm going to avoid that going forward.
The first thing to point out is that there's a system model that intended to support multiple analyses of 'what can go wrong.' ("Sample scenario...Time to do a little threat modeling.") This is a very cool demonstration of how to communicate about security along a supply chain. In this instance, the answers to "what are we working on" vary with who "we" are. That might be the Kubernetes team, or it might be someone using Kubernetes to implement a Multi-tenant SaaS workload.
What are we working on?
The answers to this are either Kubernetes or the mutli-tenant system. The post includes a nice diagram (reproduced above) of Kubernetes and its boundaries. Speaking of boundaries, they break out security boundaries which enforce the trust boundaries. I've also heard 'security boundaries' referred to as 'security barriers' or 'boundary enforcement.' They also say "At Google, we aim to protect all trust boundaries with at least two different security boundaries that each need to fail in order to cross a trust boundary."
But you can use this diagram to help you either improve Kubernetes, or to improve the security of systems hosted in Kubernetes.
What can go wrong?
Isolation failures. You get a resource isolation failure...you get a network isolation failure, everyone gets an isolation failure! Well, no, not really. You only get an isolation fail if your security boundaries fail. (Sorry! Sorry?)

This use of isolation is interestingly different from STRIDE or ATT&CK. In many threat models of userland code on a desktop, the answer is 'and then they can run code, and do all sorts of things.' The isolation failure was the end of a chain, rather than the start, and you focus on the spoof, tamper or EoP/RCE that gets you onto the chain. In that sense, isolation may seem frustratingly vague for many readers. But isolation is a useful property to have, and more importantly, it's what we're asking Kubernetes to provide.
There's also mention of cryptomining (and cgroups as a fix) and running untrusted code (use sandboxing). Especially with regards to untrusted code, I'd like to see more discussion of how to run untrusted code, which may or may not be inside a web trust boundary, semi-safely, which is to say either attempting to control its output, or safely, which is to say, in a separate web namespace.
What are we going to do about it?
You can use this model to decide what you're going to do about it. How far up or down the list of isolations should you be? Does your app need its own container, pod, node, cluster?
I would like to see more precision in the wording of the controls — what does 'some' control-pane isolation mean? Is it a level of effort to overcome, a set of things you can rely on and some you can't? The crisp expression of these qualities isn't easy, but the authors are in a better position to express them than their readers. (There may be more on this elsewhere in the series.)
Did we do a good job?
There's no explicit discussion, but my guess is that the post was vetted by a great many people.
To sum up, this is a great example of using threat modeling to communicate between supplier and customer. By drawing the model and using it to threat model, they help people decide if GCP is right, and if so, how to configure it in the most secure way.
What do you see in the models?