Threat Model Thursday: curl
Looking at a threat model for curl, the command line web client.
For Threat Model Thursday, I want to look at a fairly unusual threat model, for cURL, the command line web client. It was done by Alex Useche and Anders Helsing of Trail of Bits, and kudos to Daniel Stenberg for publishing the results. (He blogs about motive and choice here, and the report is here.)
As always, the goal of this work is to constructively engage with and learn from the threat model we’re examining. So what are we examining? It’s a threat model for cURL. It starts with context: who’s doing the work, why it’s being done. It continues with a set of system diagrams (models), and a list of threat actors and possible attack vectors, which I might call threats. That’s followed by detailed findings and a methodology section.
Generally this is solid work. It’s also unusual — I rarely see anyone threat modeling what we might initially think of as a local client binary.
The Models
Let’s start with the model. The “High-Level Data Flow” on page 8 is nice. It sets the context for what we’re looking at and how it works. I think the arrangement could be improved. Generally, time in diagrams flows like text: left to right and top to bottom, and so this diagram might be better mirrored. Also, what’s up with the local attacker and no boundary?
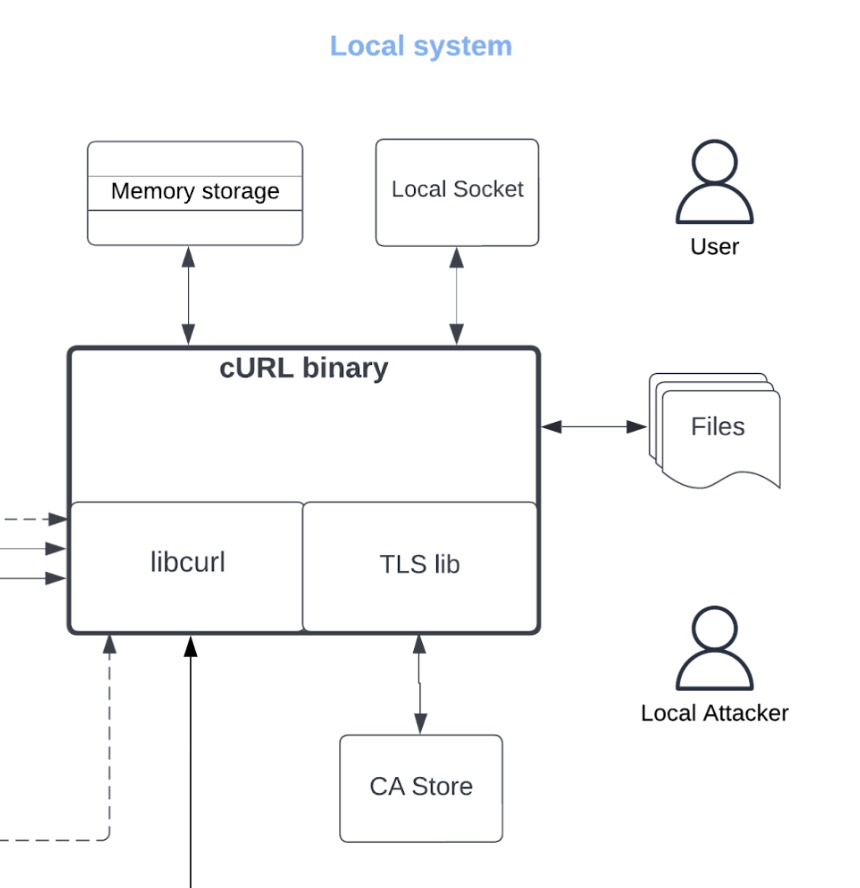
We can add trust boundaries to how the local system is portrayed. I think the CA store is owned by root, while cURL’s memory storage is in the user’s boundary. To re-draw a little, I’d like to see boundaries added, maybe like these:
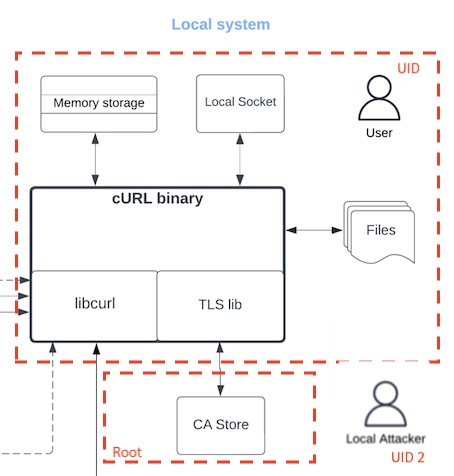
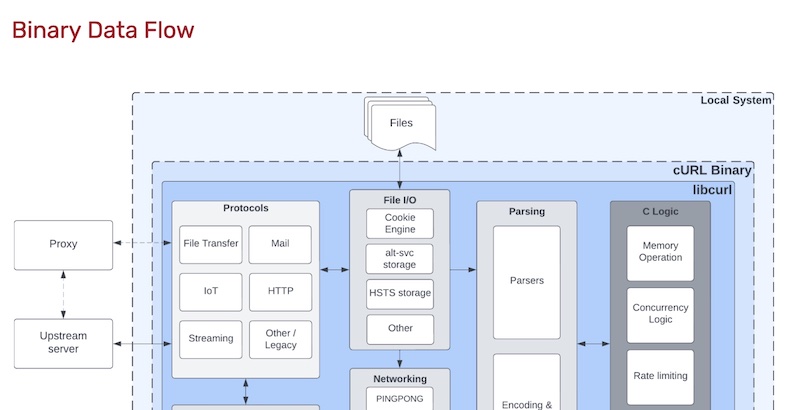
To be fair, in the binary data flow model on the next page, the CA is in a “local system” boundary, which is good. And while this diagram is interesting and I’m learning things from reading it, I’m finding myself asking: what’s the point of the binary data flow model? Clearly, a lot of work went into documenting all the things happening inside the libcurl binary, but there are no futher boundaries as I usually think of them. What are the logical blocks here? Perhaps this is an important part of the consultants, or even the developers, solidifying their mental models to help with other analysis?
The Threats
The list of attack paths includes “An attacker sitting on the same machine where cURL application is being run. Has the same or lower level of privileges as the end user.” These (“the same” and “lower”) seem like importantly different paths to me. An attacker with exactly the same privileges as the victim is largely uninteresting. There are confused deputy problems, where, say, bash, gets input from an outsider, but if there’s a case where that’s happening, perhaps we should portray it in the diagram and create a restricted version where that can be done?
The attack list is also interesting. Is “Invalid usage of libcurl by third-party application developers” really a threat which cURL can address? And what about “Flawed cross-endpoint transfers such as insufficient Same Origin Policy correctness and insecure HTTP redirects”? What should cURL do with an insecure redirect? Should I, the end user need to include --yes-pretend-to-be-a-web-browser, or should I have an option --strict-security? I don’t have an answer for this, and I’m glad to see them thinking about these issues.
I was also surprised to learn that curl includes email, telnet and even gopher. (But not archie? 🤯 do these kids have no respect for heritage?)
I don’t have a lot to add to the list of findings.
The Methodology
The methodology seems generally solid. I’m on record as saying that I’m not a fan of listing attackers, but here the attackers are characterized by position, rather than by motivation.
I was somewhat confused seeing ‘risk assessment’ as a security control. It’s listed in Appendix B, which says “Risk assessment policies, vulnerability scanning capabilities, and risk management solutions.” (To get a little meta, is this where cURL should be doing their own threat modeling of new features?)
All in all, this cURL threat model is different than models for a three-tier web app, or a mobile banking app, and it was a lot of fun to read. Thanks to the team who did the work, and to Daniel Stenberg for releasing it.